⚙️ Beyond the Basics: Scalable System Design Patterns

“Good design adds value faster than it adds cost.” — Thomas C. Gale
Preface
When engineers talk about system design, the conversation often starts with load balancers, caching, sharding, or CAP theorem. While these are the foundational pillars, they only scratch the surface. As your systems scale to millions of users and petabytes of data, the real engineering starts — where design patterns, trade-offs, and architectural styles become decisive.
In this blog, we dive into advanced system design patterns — the ones that separate a scalable system from one that’s just functional. Whether you’re preparing for an SDE3 interview, building the backend of a unicorn startup, or architecting microservices for enterprise, this guide is for you.

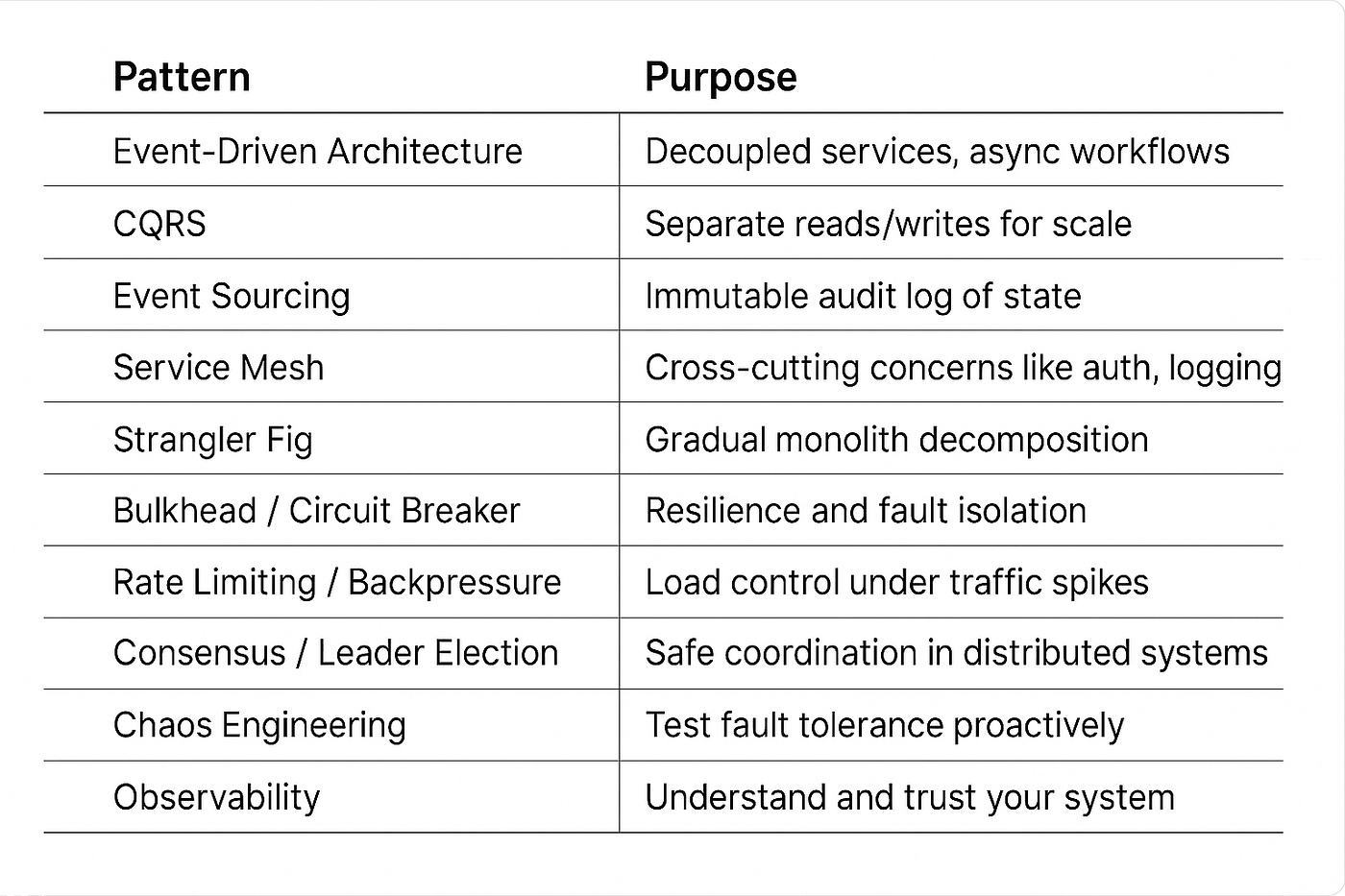
1. 🧩 Event-Driven Architecture (EDA)
Pattern: Publish-Subscribe / Event Sourcing
Core Idea: Systems communicate by producing and reacting to events asynchronously.
✅ Use When:
Components need to evolve independently.
You want to decouple microservices or modules.
Real-time data pipelines are needed (e.g., activity tracking, fraud detection).
🔧 Real-World Analogy:
Think of a stock exchange. Buyers and sellers don’t talk directly — they publish bids/offers to a central system that matches them. That’s Pub/Sub.
🔍 Tools:
Kafka, RabbitMQ, NATS
AWS SNS/SQS
EventStore for sourcing patterns
⚠️ Watch Out For:
Message loss (solve via durable queues + retries)
Ordering guarantees (consider partitioning strategies)
Debugging (introduce trace IDs and central logs)
2. ⚙️ CQRS (Command Query Responsibility Segregation)
Pattern: Separate the write (command) and read (query) sides of your application.
✅ Use When:
Read vs. write traffic is heavily imbalanced.
Different models are needed for querying and updating data.
You’re building a complex domain (e.g., banking, e-commerce).
🔧 Real-World Analogy:
In a restaurant, the kitchen (writes) and the waiter (reads) do different things. Customers don’t place orders and fetch food from the same person.
🧪 Technical Examples:
Use Postgres for transactional writes and ElasticSearch for fast reads.
Use event sourcing to update the write model and rebuild the read model asynchronously.
⚠️ Watch Out For:
Eventual consistency between read/write models.
Complex deployments — especially when debugging inconsistencies.
3. 🏗️ Strangler Pattern
Pattern: Gradually replace parts of a legacy system with new components behind a unified façade.
✅ Use When:
Migrating a monolith to microservices.
Refactoring legacy code with minimal downtime.
🔧 Real-World Analogy:
Renovating a bridge by building a new one beside it, then slowly rerouting traffic.
🧪 Technical Stack:
API Gateway (Kong, NGINX, AWS API Gateway)
Proxy all requests and reroute some to the new system.
Eventually, the legacy system is “strangled” and removed.
⚠️ Watch Out For:
Interface mismatches (handle backward compatibility).
Mixed state and duplicated logic during the transition.
4. 🌉 Circuit Breaker Pattern
Pattern: Automatically prevent requests to a service if it’s failing consistently.
✅ Use When:
A downstream service might fail or slow down.
Preventing cascading failures is critical.
🔧 Real-World Analogy:
An electric fuse cuts power when it overheats. Similarly, a circuit breaker in software “trips” if too many calls fail.
🧪 Libraries & Tools:
Resilience4j, Hystrix (deprecated), Istio, Envoy
Use in retries, timeouts, fallbacks
⚠️ Watch Out For:
Threshold tuning: false positives/negatives
Thundering herd on recovery (use jitter + exponential backoff)
5. 🛡 Bulkhead Pattern
Pattern: Partition system components so that a failure in one doesn’t crash the others.
✅ Use When:
You need to isolate resources (e.g., thread pools, containers).
One slow service should not affect the rest.
🔧 Real-World Analogy:
Ship compartments are sealed — if one floods, the ship stays afloat.
🧪 Implementation:
Use separate thread pools or async queues for each subsystem.
Kubernetes Pods with resource quotas.
⚠️ Watch Out For:
Resource underutilization due to static partitioning.
Requires accurate workload prediction to tune limits.
6. 🌐 Polyglot Persistence
Pattern: Use different database types based on the specific needs of each service or feature.
✅ Use When:
You need the right tool for the right job (graph queries vs. search vs. transactions).
Scaling and flexibility are more important than a unified backend.
🔧 Real-World Stack:
Postgres for user data
MongoDB for unstructured logs
Redis for caching
Neo4j for social graphs
ElasticSearch for search
⚠️ Watch Out For:
Data duplication and sync issues
Complex backup, restore, and migration plans
7. 🚦 Rate Limiting & Throttling
Pattern: Control how many requests users or services can make in a given timeframe.
✅ Use When:
Protecting APIs from abuse.
Preventing server overload.
🔧 Algorithms:
Token Bucket: Flexible burst handling.
Leaky Bucket: Constant outflow rate.
Sliding Window: Good for fixed time window control.
🧪 Tools:
Redis with Lua scripts
API Gateway limits
Envoy or NGINX rate modules
⚠️ Watch Out For:
State management in distributed setups.
Rate limit “leaks” due to async retries or misconfigured clients.
8. 🧱 Sharding Patterns
Pattern: Break your database into smaller, manageable parts (shards).
✅ Use When:
Vertical scaling hits limits (I/O, memory, etc.).
Latency requirements vary by geography or tenant.
🔧 Sharding Strategies:
Hash-based (good distribution, hard to rebalance)
Range-based (efficient for queries, hot partitions possible)
Geo-based (region isolation)
🧪 Infrastructure Examples:
MySQL or Postgres + custom sharding logic
Vitess (Google) or Citus (Postgres)
⚠️ Watch Out For:
Cross-shard joins and transactions.
Hot shards when skewed distribution occurs.
9. 🔁 Saga Pattern
Pattern: A sequence of local transactions coordinated via events, with compensating transactions for rollbacks.
✅ Use When:
You need to manage distributed transactions across services.
ACID transactions are too heavyweight or unavailable.
🔧 Real-World Analogy:
Booking a trip: if flight booking fails, cancel hotel and car. Each action is reversible.
🧪 Implementation Models:
Choreography: Each service listens and reacts (event-driven)
Orchestration: Central coordinator dictates flow (state machine)
⚠️ Watch Out For:
Writing correct compensating logic (idempotency, retries)
Testing all failure scenarios thoroughly
10. 🧭 Backend for Frontend (BFF)
Pattern: A custom API layer built specifically for a frontend (web, iOS, Android, etc.)
✅ Use When:
You need to optimize APIs per platform.
Frontend teams are blocked by backend coupling.
You want to abstract complexity and orchestration logic away from UIs.
🔧 Real-World Analogy:
A different concierge for each type of guest — business, tourist, or family — each gets tailored service, even if they access the same hotel.
🧪 Technical Stack:
Node.js/Express or GraphQL servers acting as BFFs
Apollo Federation to manage multi-device data needs
API gateways routing requests to correct BFF
✨ Benefits:
Tailored response formats per device.
Reduced chattiness in mobile clients.
Security boundary between client and core services.
⚠️ Watch Out For:
Code duplication across BFFs.
Added maintenance overhead if poorly scoped.
🚖 Case Study: How Uber Scales With Patterns
Uber operates in over 70 countries with real-time location tracking, dynamic pricing, and multi-leg trip planning. They rely on several of the above design patterns:
🔍 Uber’s Key Architectural Moves:
Event-Driven Architecture: Kafka and Apache Flink power asynchronous event pipelines (e.g., location updates, surge pricing, driver availability).
CQRS: Write-heavy trip creation handled by transactional stores; read-heavy maps and ETA are served from optimized read models and in-memory caches.
Bulkhead + Circuit Breakers: Prevent platform-wide outages from regional failures by isolating services per zone or region.
Saga Pattern: Trip flows across booking, dispatch, payment, and rating — each has its own rollback logic.
Backend for Frontend (BFF): Mobile clients talk to device-specific BFF APIs, which aggregate and filter data from multiple internal services.
🧠 Why It Works:
Uber has a highly geo-distributed, latency-sensitive system.
Patterns like sharding by city or region, eventual consistency in matching, and resilience-first design help meet 99.99% SLAs.
✨ Final Thoughts
Design patterns are only powerful when used intentionally. Don’t cargo-cult Netflix or Uber architectures. Instead, ask:
What’s your bottleneck: throughput, latency, or reliability?
Can this pattern reduce complexity or only shift it?
Is the trade-off worth it in your current scale?
“Build systems that are easy to change, not just easy to build.”
📚 Further Reading & Tools
📘 Designing Data-Intensive Applications — Martin Kleppmann
📘 Software Architecture Patterns — Mark Richards
🛠 Tools: Kafka, Redis, Envoy, Resilience4j, Vitess, Kubernetes, GraphQL